

Capítulo 78 – Modelo BERT – Previsão da Próxima Frase
Vamos complementar o capítulo anterior e compreender alguns detalhes do funcionamento do BERT para Processamento de Linguagem Natural.
Antes de alimentar as sequências de palavras no BERT, 15% das palavras em cada sequência são substituídas por um token [MASK]. O modelo então tenta prever o valor original das palavras mascaradas, com base no contexto fornecido pelas outras palavras não mascaradas na sequência. Em termos técnicos, a previsão das palavras de saída requer:
- Adicionar uma camada de classificação no topo da saída do codificador.
- Multiplicar os vetores de saída pela matriz de embedding, transformando-os na dimensão do vocabulário.
- Calcular a probabilidade de cada palavra do vocabulário com a função de ativação softmax.
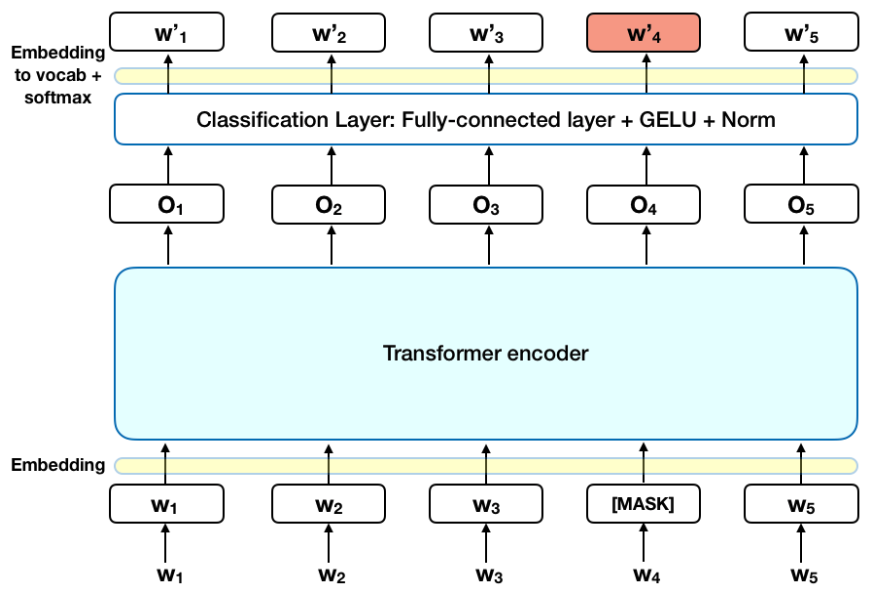
A função de perda no modelo BERT leva em consideração apenas a previsão dos valores mascarados e ignora a previsão das palavras não mascaradas. Como consequência, o modelo converge mais devagar do que os modelos direcionais, uma característica que é compensada por sua maior percepção do contexto.
Nota: na prática, a implementação de BERT é um pouco mais elaborada e não substitui todas as palavras mascaradas de 15%. Consulte o Apêndice A para obter informações adicionais.
Previsão da Próxima Frase (Next Sentence Prediction – NSP)
No processo de treinamento do BERT, o modelo recebe pares de frases como entrada e aprende a prever se a segunda frase do par é a frase subsequente no documento original. Durante o treinamento, 50% das entradas são um par em que a segunda frase é a frase subsequente no documento original, enquanto nos outros 50% uma frase aleatória do corpus é escolhida como segunda frase. A suposição é que a frase aleatória será desconectada da primeira frase.
Para ajudar o modelo a distinguir entre as duas sentenças no treinamento, a entrada é processada da seguinte maneira antes de entrar no modelo:
Um token [CLS] é inserido no início da primeira frase e um token [SEP] é inserido no final de cada frase.
Uma embedding de frase indicando a frase A ou a frase B é adicionada a cada token. Embeddings de frases são semelhantes em conceito aos embeddings de token com um vocabulário de 2.
Uma embedding posicional é adicionada a cada token para indicar sua posição na sequência. O conceito e a implementação da embedding posicional são apresentados no artigo do Transformer fornecido pelo Google (link ao final do capítulo).
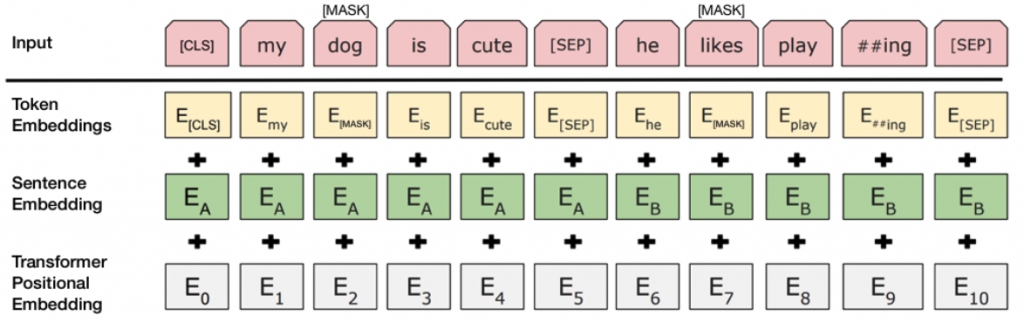
Para prever se a segunda frase está realmente conectada à primeira, as seguintes etapas são executadas:
Toda a sequência de entrada passa pelo modelo do Transformer.
A saída do token [CLS] é transformada em um vetor em forma de 2 × 1, usando uma camada de classificação simples (matrizes aprendidas de pesos e vieses).
A probabilidade de IsNextSequence é calculada com a função de ativação softmax.
Ao treinar o modelo BERT, o Mask LM (MLM) e a Previsão da Próxima Frase (NSP) são treinados em conjunto, com o objetivo de minimizar a função perda combinada das duas estratégias.
Como Usar o BERT
Usar o BERT para uma tarefa específica é relativamente simples. O BERT pode ser usado para uma ampla variedade de tarefas de linguagem, adicionando apenas uma pequena camada ao modelo central.
Tarefas de classificação, como análise de sentimento, são feitas de maneira semelhante à classificação da próxima frase, adicionando uma camada de classificação na parte superior da saída do Transformer para o token [CLS].
Em tarefas de resposta a perguntas (por exemplo, SQuAD v1.1), o software recebe uma pergunta sobre uma sequência de texto e é obrigado a marcar a resposta na sequência. Usando o BERT, um modelo de Q&A pode ser treinado aprendendo dois vetores extras que marcam o início e o fim da resposta.
No Named Entity Recognition (NER), o software recebe uma sequência de texto e é obrigado a marcar os vários tipos de entidades (Pessoa, Organização, Data, etc.) que aparecem no texto. Usando BERT, um modelo NER pode ser treinado alimentando o vetor de saída de cada token em uma camada de classificação que prevê o rótulo NER.
No treinamento de ajuste fino, a maioria dos hiperparâmetros permanecem os mesmos que no treinamento do BERT, e o artigo fornece orientação específica (Seção 3.5 do paper oficial do Google) sobre os hiperparâmetros que requerem ajuste. A equipe do BERT usou essa técnica para obter resultados de última geração em uma ampla variedade de tarefas desafiadoras de linguagem natural, detalhadas na Seção 4 do artigo.
Aprendizado
O tamanho do modelo é importante, mesmo em grande escala. BERT_large, com 345 milhões de parâmetros, é o maior modelo desse tipo. É comprovadamente superior em tarefas de pequena escala ao BERT_base, que usa a mesma arquitetura com “apenas” 110 milhões de parâmetros.
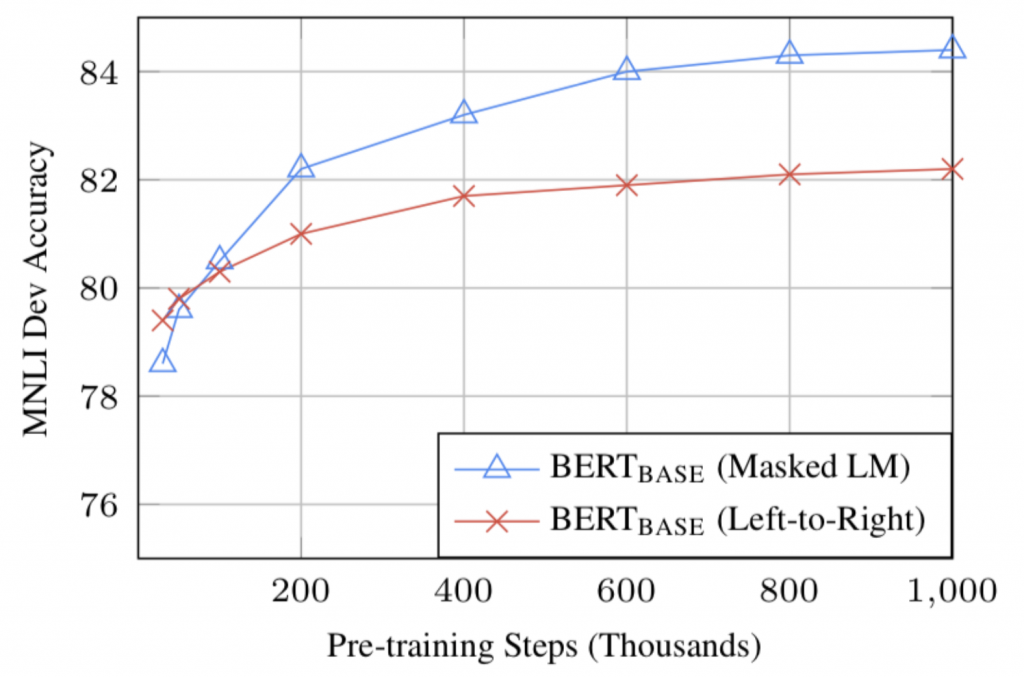
Com dados de treinamento suficientes, mais etapas de treinamento = maior precisão. Por exemplo, na tarefa MNLI, a precisão de BERT_base melhora em 1,0% quando treinada em etapas de 1M (tamanho de lote de 128.000 palavras) em comparação com 500.000 etapas com o mesmo tamanho de lote.
A abordagem bidirecional (MLM) do BERT converge mais lentamente do que as abordagens da esquerda para a direita (porque apenas 15% das palavras são previstas em cada lote), mas o treinamento bidirecional ainda supera o treinamento da esquerda para a direita após um pequeno número de etapas de pré-treinamento.
Conclusão
O BERT é, sem dúvida, um avanço no uso de Aprendizado de Máquina para Processamento de Linguagem Natural. O fato de ser acessível e permitir um ajuste fino rápido provavelmente permitirá uma ampla gama de aplicações práticas no futuro. Nos capítulos sobre BERT deste livro, procuramos descrever as principais ideias do artigo sem nos afogarmos em detalhes técnicos excessivos. Para aqueles que desejam um mergulho mais profundo, recomendamos a leitura do artigo completo e dos artigos auxiliares referenciados nele.
Outra referência útil é o código-fonte e os modelos do BERT, que cobrem 103 linguagens e foram generosamente liberados como código aberto pela equipe de pesquisa.
Apêndice A – Máscara de Palavras (MLM)
O treinamento do modelo de linguagem NO BERT é feito prevendo 15% dos tokens na entrada, que foram escolhidos aleatoriamente. Esses tokens são pré-processados da seguinte forma – 80% são substituídos por um token “[MASK]”, 10% por uma palavra aleatória e 10% usam a palavra original. A intuição que levou os autores a escolher essa abordagem é a seguinte:
Se usássemos [MASK] 100% do tempo, o modelo não produziria necessariamente boas representações de token para palavras não mascaradas. Os tokens não mascarados ainda eram usados para contexto, mas o modelo foi otimizado para prever palavras mascaradas.
Se usássemos [MASK] 90% das vezes e palavras aleatórias 10% das vezes, isso ensinaria ao modelo que a palavra observada nunca está correta.
Se usássemos [MASK] 90% do tempo e mantivéssemos a mesma palavra 10% do tempo, o modelo poderia apenas copiar trivialmente o embedding não contextual.
Nenhuma mudança foi feita nas proporções desta abordagem, e pode ter funcionado melhor com proporções diferentes. Além disso, o desempenho do modelo não foi testado simplesmente mascarando 100% dos tokens selecionados.
Referências:
Formação Processamento de Linguagem Natural 4.0
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
BERT Explained: State of the art language model for NLP
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)