

Capítulo 79 – Conhecendo o Modelo GPT-3 (Generative Pre-trained Transformer)
Os modelos Generative Pre-Training Transformer (GPT) da OpenAI conquistaram a comunidade de Processamento de Linguagem Natural (PLN) com a introdução de modelos de linguagem muito poderosos. Esses modelos podem realizar várias tarefas de PLN, como responder a perguntas, vinculação textual, resumo de texto, etc., sem nenhum treinamento supervisionado. Esses modelos de linguagem precisam de muito poucos ou nenhum exemplo para entender as tarefas e alcançar um desempenho equivalente ou até melhor do que os modelos de última geração treinados de maneira supervisionada.

Neste e nos próximos capítulos vamos cobrir a jornada desses modelos e entender como eles evoluíram ao longo de um período de 2 anos. Estaremos cobrindo os seguintes tópicos aqui:
1. Discussão do artigo GPT-1 (Improving Language Understanding by Generative Pre-training).
2. Discussão do artigo GPT-2 (Language Models are unsupervised multitask learners) e suas melhorias subsequentes em relação ao GPT-1.
3. Discussão do artigo GPT-3 (Language models are few shot learners) e as melhorias que o tornaram um dos modelos mais poderosos que o PLN já viu até agora.
Vamos abordar ainda os conceitos básicos de terminologias de PLN e arquitetura Transformer. Os modelos GPT vão estar presentes na Formação IA Aplicada ao Direito, na Data Science Academy.
Vamos começar conhecendo o membro mais jovem da família com uma visão geral do modelo e da sua história.
O Que é o GPT-3?
Recentemente estávamos discutindo se a implementação do Generative Pretrained Transformer-2 (GPT-2) era razoável. Se o debate parece recente, é porque é (escrito a partir de 2020): O notório modelo GPT-2 foi anunciado pela OpenAI em fevereiro de 2019, mas não foi totalmente lançado até quase 9 meses depois (embora tenha sido replicado antes disso). O cronograma de lançamento foi admitidamente um tanto experimental mais para fomentar a discussão da publicação de forma aberta responsável, ao invés de um último esforço para evitar um apocalipse da IA. Isso não impediu os críticos de questionar as vantagens publicitárias de um ciclo de lançamento ameaçador.
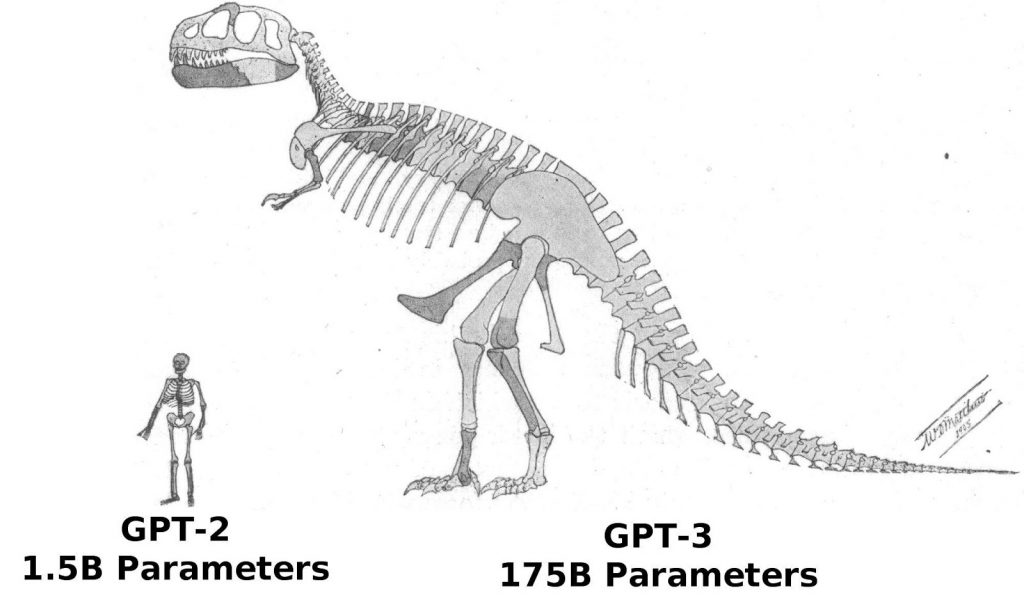
Tudo isso é um pouco discutível agora, porque a OpenAI não apenas treinou um modelo de linguagem muito maior no GPT-3, mas você pode se inscrever para acessá-lo por meio de sua nova API. Comparar GPT-3 com GPT-2 é como comparar maçãs com passas, porque o modelo é muito maior. Enquanto o GPT-2 pesava apenas 1,542 bilhão de parâmetros (com versões de lançamento menores em 117, 345 e 762 milhões), o GPT-3 de tamanho completo tem 175 bilhões de parâmetros. GPT-3 também foi combinado com um conjunto de dados maior para pré-treinamento: 570 GB de texto em comparação com 40 GB para o GPT-2.
GPT-3 é um modelo de linguagem alimentado por rede neural. Um modelo de linguagem é um modelo que prevê a probabilidade de uma frase existir no mundo. Por exemplo, um modelo de linguagem pode rotular a frase “Eu levo meu cachorro para passear” como mais provável de existir (ou seja, na Internet) do que a frase “Eu levo minha banana para passear”. Isso é verdadeiro tanto para sentenças quanto para frases e, de maneira mais geral, qualquer sequência de caracteres.
GPT-3 é o maior transformador de processamento de linguagem natural (PLN) lançado até agora, eclipsando o recorde anterior, o Turing-NLG da Microsoft Research com 17 bilhões de parâmetros, em cerca de 10 vezes. Não é novidade que houve bastante empolgação em torno do modelo e, dada a abundância de demonstrações de GPT-3 no Twitter e em outros lugares, a OpenAI aparentemente conseguiu acomodar bem o fornecimento de acesso beta à nova API. Isso resultou em uma explosão de demos: algumas boas, outras ruins, todas interessantes. Algumas dessas demos agora estão sendo apresentadas como produtos a serem lançados em breve e, em alguns casos, podem até ser úteis. Uma coisa é certa, PLN conseguiu uma notória evolução.
Como a maioria dos modelos de linguagem, o GPT-3 é elegantemente treinado em um conjunto de dados de texto não rotulado. Palavras ou frases são removidas aleatoriamente do texto, e o modelo deve aprender a preenchê-las usando apenas as palavras ao redor como contexto. É uma tarefa de treinamento simples que resulta em um modelo poderoso e generalizável.
A própria arquitetura do modelo GPT-3 é uma rede neural baseada em transformador. Essa arquitetura se tornou popular cerca de 2 a 3 anos atrás e é a base para o popular modelo de PLN BERT que abordamos nos capítulos anteriores. Do ponto de vista da arquitetura, o GPT-3 não é muito novo! Então, o que o torna tão especial e mágico?
É REALMENTE GRANDE. Quero dizer muito grande. Com 175 bilhões de parâmetros, é o maior modelo de linguagem já criado (GPT-2 tinha apenas 1,5 bilhão de parâmetros!), E foi treinado no maior conjunto de dados de qualquer modelo de linguagem. Esta, ao que parece, é a principal razão pela qual o GPT-3 é tão impressionante.
E aqui está a parte mágica. Como resultado, o GPT-3 pode fazer o que nenhum outro modelo pode fazer (bem): executar tarefas específicas sem nenhum ajuste especial. Você pode pedir ao GPT-3 para ser um tradutor, um programador, um poeta ou um autor famoso, e pode fazê-lo com menos de 10 exemplos de treinamento. É o mais próximo que chegamos de uma IA genérica, como descrito no famoso livro O Algoritmo Mestre.
A maioria dos outros modelos (como o BERT) requer uma etapa de ajuste fino elaborada, onde você reúne milhares de exemplos de pares de frases (digamos) francês-inglês para ensiná-lo a traduzir. Com o GPT-3, você não precisa fazer aquela etapa de ajuste fino. Este é o cerne da questão. Isso é o que deixa as pessoas entusiasmadas com o GPT-3: tarefas de linguagem personalizadas sem dados de treinamento.
Nos próximos capítulos vamos compreender como surgiu o GPT-3, seus antecessores e funcionamento.
Referências: