

Capítulo 77 – Modelo BERT Para Processamento de Linguagem Natural
BERT (Bidirectional Encoder Representations from Transformers) é um modelo de Deep Learning criado por pesquisadores do Google AI Language. O BERT causou um rebuliço na comunidade de aprendizado de máquina ao apresentar resultados de última geração em uma ampla variedade de tarefas de PLN (Processamento de Linguagem Natural), incluindo respostas automáticas ao banco de dados de perguntas (SQuAD v1.1), inferência de linguagem natural (MNLI) e outras tarefas.
Vamos conhecer um pouco mais em detalhes o que é e como funciona o Modelo BERT Para Processamento de Linguagem Natural.
Principal Inovação
A principal inovação técnica do BERT é a aplicação do treinamento bidirecional do Transformer (um modelo de atenção) à modelagem de linguagem. Isso é diferente dos esforços anteriores que olhavam para uma sequência de texto da esquerda para a direita ou treinamento combinado da esquerda para a direita e da direita para a esquerda. Os resultados do BERT mostram que é um modelo de linguagem treinado bidirecionalmente que pode ter um senso mais profundo de contexto e fluxo de linguagem do que modelos de linguagem de direção única. No artigo original do BERT (link nas referências), os pesquisadores detalham uma nova técnica chamada Masked LM (MLM), que permite o treinamento bidirecional em modelos nos quais era impossível anteriormente.
Transfer Learning
No campo da Visão Computacional, os pesquisadores têm mostrado repetidamente o valor da aprendizagem por transferência (Transfer Learning) – pré-treinar um modelo de rede neural em uma tarefa conhecida, por exemplo ImageNet, e depois realizar o ajuste fino – usando a rede neural treinada como base de um novo modelo de propósito específico. Nos últimos anos, pesquisadores têm mostrado que uma técnica semelhante pode ser útil em muitas tarefas de linguagem natural.
Uma abordagem diferente, que também é popular em tarefas de PLN e exemplificada no recente artigo do ELMo, é o treinamento baseado em recursos. Nesta abordagem, uma rede neural pré-treinada produz embeddings de palavras que são então usados como recursos em modelos de PLN.
Como Funciona o BERT
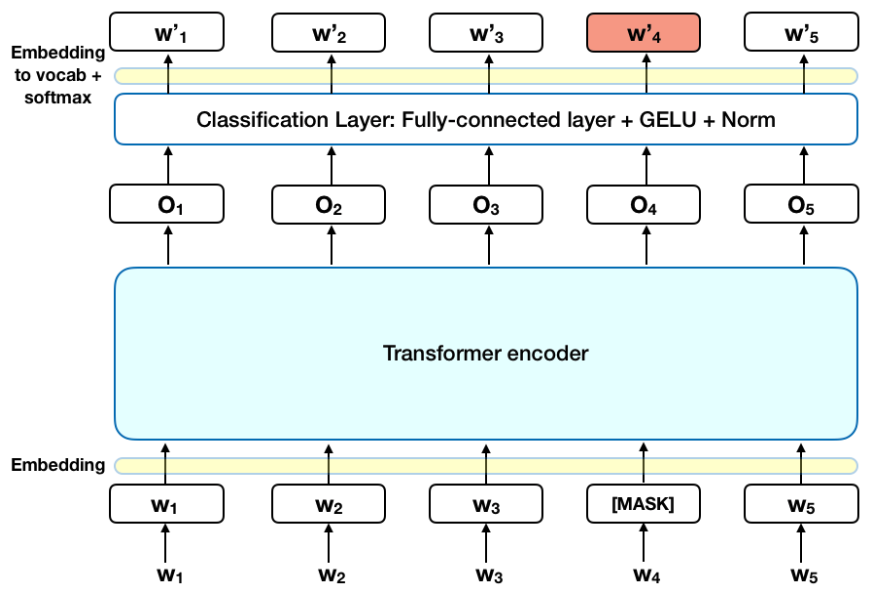
O BERT faz uso do Transformer, um mecanismo de atenção que aprende as relações contextuais entre palavras (ou subpalavras) em um texto. Em sua forma original, o Transformer inclui dois mecanismos separados – um codificador que lê a entrada de texto e um decodificador que produz uma previsão para a tarefa. Como o objetivo do BERT é gerar um modelo de linguagem, apenas o mecanismo do codificador é necessário.
Ao contrário dos modelos direcionais, que lêem a entrada de texto sequencialmente (da esquerda para a direita ou da direita para a esquerda), o codificador Transformer lê toda a sequência de palavras de uma vez. Portanto, é considerado bidirecional, embora seja mais preciso dizer que é não direcional. Esta característica permite que o modelo aprenda o contexto de uma palavra com base em todos os seus arredores (esquerdo e direito da palavra).
O gráfico abaixo é uma descrição de alto nível do codificador Transformer. A entrada é uma sequência de tokens, que são primeiro incorporados em vetores e depois processados na rede neural. A saída é uma sequência de vetores de tamanho H, em que cada vetor corresponde a um token de entrada com o mesmo índice.
Ao treinar modelos de linguagem, existe o desafio de definir uma meta de previsão. Muitos modelos prevêem a próxima palavra em uma sequência (por exemplo, “A criança voltou para casa de ___”), uma abordagem direcional que limita inerentemente o aprendizado do contexto.
Para superar esse desafio, o BERT usa duas estratégias de treinamento: Masked LM (MLM) e Next Sentence Prediction (NSP), que estudaremos no próximo capítulo.
Referências:
Formação Processamento de Linguagem Natural 4.0
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
BERT Explained: State of the art language model for NLP
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)