

Capítulo 64 – Componentes do Aprendizado Por Reforço (Reinforcement Learning)
O Aprendizado Por Reforço pode ser entendido através de seus componentes: agente, ambiente, estados, ações e recompensas, todos os quais explicaremos neste capítulo. Letras maiúsculas indicarão conjuntos de objetos e letras minúsculas indicarão um objeto específico. Por exemplo: A são todas as ações possíveis, enquanto a é uma ação específica contida no conjunto.
Agente: um agente executa ações; por exemplo, um drone fazendo uma entrega ou Super Mario navegando em um videogame. O algoritmo é o agente. Pode ser útil considerar que, na vida, o agente é você.
Ação (A): A é o conjunto de todos os movimentos possíveis que o agente pode fazer. Uma ação é quase autoexplicativa, mas deve-se notar que os agentes geralmente escolhem de uma lista de ações possíveis e discretas. Nos videogames, a lista pode incluir correr para a direita ou para a esquerda, pular alto ou baixo, agachar-se ou ficar parado. Nos mercados de ações, a lista pode incluir a compra, venda ou manutenção de qualquer um de uma matriz de ativos financeiros e seus derivativos. Ao lidar com drones, as alternativas incluiriam muitas velocidades e acelerações diferentes no espaço 3D.
Fator de desconto: O fator de desconto é multiplicado por recompensas futuras, conforme descoberto pelo agente, a fim de amortecer o efeito dessas recompensas na escolha de ação do agente. Por quê? Ele foi projetado para fazer com que as recompensas futuras valham menos que as recompensas imediatas; isto é, aplica um tipo de hedonismo de curto prazo no agente. Geralmente expressa com a letra grega minúscula gama: γ. Se γ for 0,8 e houver uma recompensa de 10 pontos após três etapas de tempo, o valor atual dessa recompensa será de 0,8³ x 10. Um fator de desconto de 1 faria as recompensas futuras valerem tanto quanto as recompensas imediatas. Estamos lutando contra o imediatismo aqui. O agente deve escolher as ações que levam à melhor solução global possível, não apenas a melhor solução imediata.
Ambiente: O mundo pelo qual o agente se move e que responde ao agente. O ambiente toma o estado atual e a ação do agente como entrada e retorna como saída a recompensa do agente e seu próximo estado. Se você é o agente, o ambiente pode ser as leis da física e as regras da sociedade que processam suas ações e determinam as consequências delas.
Estado (S): Um estado é uma situação concreta e imediata em que o agente se encontra; ou seja, um local e momento específico, uma configuração instantânea que coloca o agente em relação a outras coisas importantes, como ferramentas, obstáculos, inimigos ou prêmios. Pode ser a situação atual retornada pelo ambiente ou qualquer situação futura. Você já esteve no lugar errado na hora errada? Isso é um estado.
Recompensa (R): Uma recompensa é o feedback pelo qual medimos o sucesso ou o fracasso das ações de um agente em um determinado estado. Por exemplo, em um videogame, quando Mario toca uma moeda, ele ganha pontos. A partir de qualquer estado, um agente envia a saída na forma de ações para o ambiente, e o ambiente retorna o novo estado do agente (que resultou da ação no estado anterior), bem como recompensas, se houver. As recompensas podem ser imediatas ou atrasadas. Eles avaliam efetivamente a ação do agente.
Política (π): A política é a estratégia que o agente emprega para determinar a próxima ação com base no estado atual. Ele mapeia estados para ações, as ações que prometem a maior recompensa.
Valor (V): O retorno esperado a longo prazo com desconto, em oposição à recompensa de curto prazo R. Vπ (s) é definido como o retorno esperado a longo prazo do estado atual sob a política π. Descontamos as recompensas ou diminuímos seu valor estimado, quanto mais futuro elas ocorrerem. E lembre-se de Keynes: “A longo prazo, estamos todos mortos”. É por isso que você desconta recompensas futuras. É útil distinguir.
Valor Q ou Valor da Ação (Q): O valor Q é semelhante ao Valor, exceto pelo fato de ser necessário um parâmetro extra, a ação atual a. Qπ (s, a) refere-se ao retorno a longo prazo de uma ação que executa uma ação sob política π do estado atual s. Q mapeia pares de ação e estado para recompensas. Observe a diferença entre Q e política.
Trajetória: Uma sequência de estados e ações que influenciam esses estados. A vida de um agente é apenas uma bola lançada alta e arqueando-se no espaço-tempo sem ser perturbada, como os humanos no mundo moderno.
Distinções Principais: Recompensa é um sinal imediato recebido em um determinado estado, enquanto valor é a soma de todas as recompensas que você pode antecipar desse estado. Valor é uma expectativa de longo prazo, enquanto recompensa é um prazer imediato. O valor é comer salada de espinafre no jantar, antecipando uma vida longa e saudável; recompensa é comer hamburguer com batata frita e refrigerante para o jantar e comprometer sua saúde futura. Eles diferem em seus horizontes temporais. Assim, você pode ter estados em que o valor e a recompensa divergem: você pode receber uma recompensa baixa e imediata (espinafre), mesmo quando se move para uma posição com grande potencial de valor a longo prazo; ou você pode receber uma alta recompensa imediata (hamburguer com batata frita e refrigerante) que leva à diminuição das perspectivas ao longo do tempo. É por isso que a função de valor, em vez de recompensas imediatas, é o que o aprendizado por reforço procura prever e controlar.
Portanto, ambientes são funções que transformam uma ação executada no estado atual no próximo estado e uma recompensa; agentes são funções que transformam o novo estado e recompensam na próxima ação. Podemos conhecer e definir a função do agente, mas na maioria das situações em que é útil e interessante aplicar o aprendizado por reforço, não sabemos a função do ambiente. É uma caixa preta onde só vemos as entradas e saídas. É como o relacionamento da maioria das pessoas com a tecnologia: sabemos o que faz, mas não sabemos como funciona. O aprendizado por reforço representa a tentativa de um agente de aproximar a função do ambiente, para que possamos enviar ações para o ambiente de caixa preta que maximize as recompensas que ele distribui.
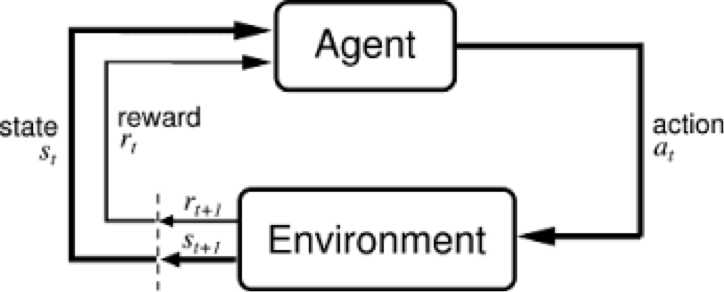
No loop de feedback acima, os subscritos indicam as etapas de tempo t e t + 1, cada uma das quais se refere a estados diferentes: o estado no momento t e o estado no momento t + 1. Diferente de outras formas de aprendizado de máquina – como aprendizado supervisionado e não supervisionado – o aprendizado por reforço só pode ser pensado sequencialmente em termos de pares de ação de estado que ocorrem um após o outro.
O aprendizado por reforço julga as ações pelos resultados que elas produzem. É orientado a objetivos, e seu objetivo é aprender sequências de ações que levarão um agente a atingir seu objetivo ou maximizar sua função objetivo. aqui estão alguns exemplos:
Nos videogames, o objetivo é terminar o jogo com mais pontos, para que cada ponto adicional obtido ao longo do jogo afete o comportamento subsequente do agente; ou seja, o agente pode aprender que deve atirar em navios de guerra, tocar em moedas ou desviar de meteoros para maximizar sua pontuação.
No mundo real, o objetivo pode ser que um robô viaje do ponto A ao ponto B, e cada centímetro que o robô é capaz de se aproximar do ponto B pode ser contado como pontos. Aqui está um exemplo de uma função objetiva para o aprendizado por reforço; ou seja, a maneira como define seu objetivo:
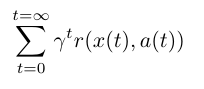
Estamos somando a função de recompensa r sobre t, que significa etapas de tempo. Portanto, essa função objetivo calcula toda a recompensa que poderíamos obter executando, digamos, um jogo. Aqui, x é o estado em um determinado momento, a é a ação executada nesse estado e r é a função de recompensa para x e a.
Outro exemplo é a otimização de portfólios financeiros (uma das principais aplicações atuais da Aprendizagem Por Reforço). Dado o volume de movimentação de diversos ativos financeiros, o agente procura a melhor combinação possível de investimentos que garanta o maior retorno financeiro no longo prazo. Essa é a tecnologia por trás dos Robôs Investidores e que ensinamos em detalhes em Engenharia Financeira com Inteligência Artificial.
Quer aprender um pouco da Matemática desta incrível técnica de aprendizagem de máquina e como ela se relaciona com Deep Learning? Então acompanhe os próximos capítulos.
Referências:
Customizando Redes Neurais com Funções de Ativação Alternativas
A Beginner’s Guide to Deep Reinforcement Learning
What is reinforcement learning? The complete guide
Applications of Reinforcement Learning in Real World
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition