

Capítulo 63 – Aplicações da Aprendizagem Por Reforço no Mundo Real
Enquanto as Redes Neurais Convolucionais (CNNs) e as Redes Neurais Recorrentes (RNNs) estão se tornando cada vez mais importantes para as empresas devido às suas aplicações em Visão Computacional e Processamento de Linguagem Natural, o Aprendizado por Reforço como uma estrutura para a neurociência computacional de um modelo para o processo de tomada de decisão parece estar subvalorizado. A Aprendizagem Por Reforço não deve ser negligenciada no espaço da pesquisa corporativa, dados seus enormes potenciais em auxiliar na tomada de decisões.
O Aprendizado por Reforço (ou Reinforcement Learning – RL), conhecido como modelo de aprendizado semi-supervisionado em Machine Learning, é uma técnica para permitir que um agente tome ações e interaja com um ambiente, a fim de maximizar as recompensas totais. Aprendizado por Reforço é geralmente modelado como um Processo de Decisão de Markov (MDP) e estudaremos isso em mais detalhes nos capítulos seguintes.
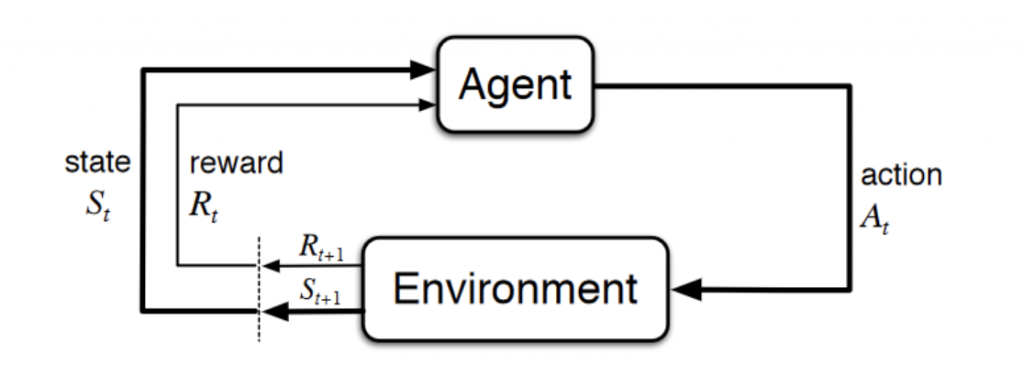
Mas aqui vai uma explicação bem simples e objetiva para ajudar a compreender o conceito:
Imagine que um bebê recebe um controle remoto da TV em sua casa (ambiente). Em termos simples, o bebê (agente) primeiro observará e construirá sua própria representação do ambiente (estado). Em seguida, o bebê curioso executará certas ações, como pressionar o controle remoto (ação) e observará a resposta da TV (próximo estado). Como uma TV não responde e é monótona, o bebê não gosta dela (recebendo uma recompensa negativa) e realiza menos ações que levarão a esse resultado (atualização da política) e vice-versa. O bebê repetirá o processo até encontrar uma política (o que fazer em diferentes circunstâncias) com a qual está satisfeito (maximizar as recompensas totais (com desconto)). Isso é o Aprendizado por Reforço. Lembre-se que em Machine Learning o que fazemos é tentar reproduzir o aprendizado humano através de diferentes técnicas.
O estudo da Aprendizagem Por Reforço é construir uma estrutura matemática para resolver problemas. Por exemplo, para encontrar uma boa política, poderíamos usar métodos baseados em valores, como Q-learning, para medir o quão boa é uma ação em um determinado estado ou métodos baseados em políticas para descobrir diretamente quais ações executar em diferentes estados sem saber quão boas as ações são.
No entanto, os problemas que enfrentamos no mundo real podem ser extremamente complicados de várias maneiras diferentes e, portanto, um algoritmo típico de Aprendizagem Por Reforço não tem nenhuma pista para resolver. Por exemplo, o espaço de estado é muito grande no jogo do GO, o ambiente não pode ser totalmente observado no jogo de pôquer e há muitos agentes interagindo entre si no mundo real. Os pesquisadores inventaram métodos para resolver alguns dos problemas usando redes neurais profundas para modelar as políticas desejadas, funções de valor ou mesmo os modelos de transição, que, portanto, são chamados de Aprendizado por Reforço Profundo (Deep Reinforcement Learning).
Mas abordaremos tudo isso em detalhes mais a frente. Por hora, vejamos algumas das principais aplicações da Aprendizagem Por Reforço.
Gerenciamento de Recursos em Clusters de Computadores
Projetar algoritmos para alocar recursos limitados a diferentes tarefas é desafiador e requer heurísticas geradas por humanos. O artigo “Gerenciamento de recursos com aprendizado por reforço profundo” explica como usar o RL para aprender automaticamente a alocar e programar recursos de computador para jobs em espera, com o objetivo de minimizar a desaceleração média do job (tarefa).
O espaço de estados foi formulado como a alocação de recursos atual e o perfil de recursos dos jobs. Para o espaço de ação, eles usaram um truque para permitir que o agente escolha mais de uma ação a cada etapa do tempo. A recompensa era a soma de (-1 / duração do job) em todos os jobs no sistema. Em seguida, eles combinaram o algoritmo REINFORCE e o valor da linha de base para calcular os gradientes da política e encontrar os melhores parâmetros de política que fornecem a distribuição de probabilidade das ações para minimizar o objetivo.
Controle de Semáforo
No artigo “Sistema multiagente baseado em aprendizado por reforço para controle de sinais de tráfego de rede”, os pesquisadores tentaram projetar um controlador de semáforo para resolver o problema de congestionamento. Testados apenas em ambiente simulado, seus métodos mostraram resultados superiores aos métodos tradicionais e lançaram uma luz sobre os possíveis usos da RL de múltiplos agentes no projeto de sistemas de tráfego.
Cinco agentes foram colocados na rede de tráfego de cinco cruzamentos, com um agente RL no cruzamento central para controlar a sinalização de tráfego. O estado foi definido como um vetor de oito dimensões, com cada elemento representando o fluxo de tráfego relativo de cada faixa. Oito opções estavam disponíveis para o agente, cada uma representando uma combinação de fases, e a função de recompensa foi definida como redução no atraso em comparação com o passo anterior. Os autores usaram o DQN para aprender o valor Q dos pares {state, action}.
Robótica
Há um incrível trabalho na aplicação de RL em robótica. Recomendamos a leitura desse paper com o resultado de uma pesquisa de RL em robótica. Neste outro trabalho, os pesquisadores treinaram um robô para aprender políticas para mapear imagens de vídeo brutas para as ações do robô. As imagens RGB foram alimentadas em uma CNN e as saídas foram os torques do motor. O componente RL era a pesquisa de política guiada para gerar dados de treinamento provenientes de sua própria distribuição de estado.
Configuração de Sistemas Web
Existem mais de 100 parâmetros configuráveis em um Sistema Web e o processo de ajuste dos parâmetros requer um operador qualificado e vários testes de rastreamento e erro. O artigo “Uma abordagem de aprendizado por reforço à auto-configuração do sistema Web on-line” mostrou a primeira tentativa no domínio sobre como fazer a reconfiguração autônoma de parâmetros em sistemas web multicamada em ambientes dinâmicos baseados em VM.
O processo de reconfiguração pode ser formulado como um MDP finito. O espaço de estado era a configuração do sistema, o espaço de ação era {aumentar, diminuir, manter} para cada parâmetro e a recompensa era definida como a diferença entre o tempo de resposta pretendido e o tempo de resposta medido. Os autores usaram o algoritmo de Q-learning para executar a tarefa.
Embora os autores tenham usado alguma outra técnica, como a inicialização de políticas, para remediar o grande espaço de estados e a complexidade computacional do problema, em vez das combinações potenciais de RL e rede neural, acredita-se que o trabalho pioneiro tenha preparado o caminho para futuras pesquisas nessa área. .
Química
O RL também pode ser aplicado na otimização de reações químicas. Pesquisadores mostraram que seu modelo superou um algoritmo de última geração e generalizou para mecanismos subjacentes diferentes no artigo “Otimizando reações químicas com aprendizado de reforço profundo”.
Combinado com o LSTM para modelar a função de política, o agente RL otimizou a reação química com o processo de decisão de Markov (MDP) caracterizado por {S, A, P, R}, em que S era o conjunto de condições experimentais (como temperatura, pH, etc), A foi o conjunto de todas as ações possíveis que podem alterar as condições experimentais, P foi a probabilidade de transição da condição atual da experiência para a próxima condição e R foi a recompensa que é uma função do estado.
A aplicação é excelente para demonstrar como a RL pode reduzir o trabalho demorado e de tentativa e erro em um ambiente relativamente estável.
Recomendações Personalizadas
O trabalho de recomendações de notícias sempre enfrentou vários desafios, incluindo a dinâmica de mudança rápida das notícias, os usuários que se cansam facilmente e a Taxa de Cliques que não pode refletir a taxa de retenção de usuários. Guanjie et al. aplicaram RL no sistema de recomendação de notícias em um documento intitulado “DRN: Uma Estrutura de Aprendizado de Reforço Profundo para Recomendação de Notícias” para combater os problemas.
Na prática, eles construíram quatro categorias de recursos, a saber: A) recursos do usuário, B) recursos de contexto como os recursos de estado do ambiente, C) recursos de notícias do usuário e D) recursos de notícias como os recursos de ação. Os quatro recursos foram inseridos na Deep Q-Network (DQN) para calcular o valor Q. Uma lista de notícias foi escolhida para recomendar com base no valor Q, e o clique do usuário nas notícias foi parte da recompensa que o agente da RL recebeu.
Os autores também empregaram outras técnicas para resolver outros problemas desafiadores, incluindo repetição de memória, modelos de sobrevivência, Dueling Bandit Gradient Descent e assim por diante.
Leilões e Publicidade
Pesquisadores do Alibaba Group publicaram um artigo “Leilões em tempo real com aprendizado de reforço de agentes múltiplos em publicidade gráfica” e afirmaram que sua solução distribuída de agentes múltiplos baseada em cluster (DCMAB) alcançou resultados promissores e, portanto, planejam realizar uma teste ao vivo na plataforma Taobao.
De um modo geral, a plataforma de anúncios Taobao é um local para os comerciantes fazerem um lance para exibir anúncios para os clientes. Isso pode ser um problema de vários agentes, porque os comerciantes fazem lances uns contra os outros e suas ações são inter-relacionadas. No artigo, comerciantes e clientes foram agrupados em diferentes grupos para reduzir a complexidade computacional. O espaço de estado dos agentes indicava o status de custo-receita dos agentes, o espaço de ação era o lance (contínuo) e a recompensa era a receita causada pelo cluster de clientes.
Talvez você esteja curioso por saber como seria o algoritmo para resolver esse tipo de problema. Aqui está o algoritmo criado pelos pesquisadores (mais detalhes no paper da pesquisa, no link anterior):

Jogos
A RL é tão conhecida hoje em dia porque é o algoritmo convencional usado para resolver jogos diferentes e às vezes alcançar um desempenho super-humano.
O mais famoso deve ser AlphaGo e AlphaGo Zero. O AlphaGo, treinado com inúmeros jogos humanos, já alcançou um desempenho super-humano usando a rede de valor e a pesquisa de árvores Monte Carlo (MCTS) em sua rede de políticas. No entanto, os pesquisadores tentaram uma abordagem mais pura da RL – treinando-a do zero. Os pesquisadores deixaram o novo agente, AlphaGo Zero, jogar sozinho e finalmente derrotar o AlphaGo 100-0.
Aprendizagem Profunda (Deep Learning)
Mais e mais tentativas de combinar RL e outras arquiteturas de aprendizado profundo podem ser vistas recentemente e mostraram resultados impressionantes.
Um dos trabalhos mais influentes da RL é o trabalho pioneiro da Deepmind para combinar a CNN com a RL. Ao fazer isso, o agente tem a capacidade de “ver” o ambiente por meio de sensores de alta dimensão e depois aprender a interagir com ele.
RL e RNN são outras combinações usadas pelas pessoas para tentar novas ideias. RNN é um tipo de rede neural que possui “memórias”. Quando combinada com a RL, a RNN oferece aos agentes a capacidade de memorizar as coisas. Por exemplo, combinaram LSTM com RL para criar uma profunda rede Q recorrente (DRQN) para jogar jogos do Atari 2600. Também usaram RNN e RL para resolver problemas de otimização de reações químicas.
O Deepmind mostrou como usar modelos generativos e RL para gerar programas. No modelo, o agente treinado adversamente usou o sinal como recompensa para melhorar as ações, em vez de propagar os gradientes para o espaço de entrada como no treinamento da GAN. Incrível, não?
O Que Você Precisa Saber Antes de Aplicar a RL ao seu Problema?
Existem várias coisas necessárias para que a RL possa ser aplicada.
Entendendo seu problema: Você não precisa necessariamente usar RL no seu problema e, às vezes, simplesmente não pode usá-lo. Convém verificar se o seu problema possui algumas das seguintes características antes de decidir usar a RL:
- a) tentativa e erro (você pode aprender a fazer melhor recebendo comentários do ambiente);
- b) recompensas atrasadas;
- c) pode ser modelado como MDP;
- d) seu problema é um problema de controle.
Um ambiente simulado: Muitas iterações são necessárias antes que um algoritmo RL funcione. Tenho certeza de que você não quer ver um agente de RL tentando coisas diferentes em um carro autônomo em uma rodovia, certo? Portanto, é necessário um ambiente simulado que possa refletir corretamente o mundo real.
MDP: Seu mundo precisa formular seu problema em um MDP. Você precisa projetar o espaço de estado, o espaço de ação, a função de recompensa e assim por diante. Seu agente fará o que é recompensado sob as restrições. Você pode não obter os resultados desejados se projetar as coisas de maneira diferente.
Algoritmos: Existem diferentes algoritmos de RL que você pode escolher e perguntas a serem feitas. Você deseja descobrir diretamente a política ou deseja aprender a função de valor? Você quer ir livre de modelo ou baseado em modelo? Você precisa combinar outros tipos de rede ou métodos neurais profundos para resolver seus problemas?
Intuições de Outras Disciplinas
RL tem uma relação muito estreita com psicologia, biologia e neurociência. Se você pensar bem, o que um agente de RL faz é apenas tentativa e erro: aprende o quão bom ou ruim suas ações são baseadas nas recompensas que recebe do ambiente. E é exatamente assim que o ser humano aprende a tomar uma decisão. Além disso, o problema de exploração, o problema de cessão de recompensa/penalidade, as tentativas de modelar o ambiente também são algo que enfrentamos em nossa vida cotidiana.
A teoria da economia também pode lançar alguma luz sobre RL. Em particular, a análise da aprendizagem de reforço multi-agente (MARL) pode ser entendida a partir das perspectivas da teoria dos jogos, que é uma área de pesquisa desenvolvida por John Nash para entender as interações de agentes em um sistema. Além da teoria dos jogos, o MARL, Processo de Decisão Markov Parcialmente Observável (POMDP) também pode ser útil para entender outros tópicos econômicos, como estrutura de mercado (por exemplo, monopólio, oligopólio, etc.), externalidade e assimetria de informação.
O que a Aprendizagem Por Reforço Pode Alcançar no Futuro?
A Aprendizagem Por Reforço seria influente e impactante das seguintes maneiras:
Assistência humana: Talvez seja exagero dizer que a RL pode um dia evoluir para inteligência geral artificial (AGI), mas a RL certamente tem o potencial de ajudar e trabalhar com pessoas. Imagine um robô ou um assistente virtual trabalhando com você e levando suas ações em consideração para executar ações a fim de alcançar um objetivo comum. Não seria ótimo?
Entendendo as consequências de diferentes estratégias: A vida é incrível, porque o tempo não volta e as coisas acontecem apenas uma vez. No entanto, às vezes gostaríamos de saber como as coisas poderiam ser diferentes (pelo menos a curto prazo) se eu adotasse uma ação diferente. A Croácia teria uma chance maior de ganhar a Copa do Mundo de 2018 se o treinador usasse outra estratégia? Obviamente, para conseguir isso, precisaríamos modelar perfeitamente o ambiente, as funções de transição e assim por diante e também analisar as interações entre os agentes.
As possibilidade são muitas e por isso Inteligência Artificial é um dos temas mais quentes do momento e os profissionais atentos a isso, ficarão com as melhores oportunidades. Continuaremos no próximo capítulo!
Referências:
Customizando Redes Neurais com Funções de Ativação Alternativas
What is reinforcement learning? The complete guide
Applications of Reinforcement Learning in Real World
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Recurrent neural network based language model
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition