

Capítulo 88 – Como Funcionam os Transformadores em Processamento de Linguagem Natural – Parte 3
Vamos seguir nossa discussão sobre os Transformadores com a parte mais importante, a Auto-Atenção. Este capítulo considera que você leu os capítulos anteriores.
Auto-Atenção: O Encoder do Transformer
O que é Auto-Atenção?
“A Auto-Atenção, às vezes chamada de Intra-Atenção, é um mecanismo de atenção que relaciona diferentes posições de uma única sequência para computar uma representação da sequência.” ~ Ashish Vaswani et al. do Google Brain.
A Auto-Atenção nos permite encontrar correlações entre diferentes palavras de entrada, indicando a estrutura sintática e contextual da frase (e por isso os Transformadores, que são baseados na Auto-Atenção, são muito utilizados em Processamento de Linguagem Natural).
Vamos tomar como exemplo a sequência de entrada “Hello, I love you” (Olá, Eu te amo). Uma camada de Auto-Atenção treinada associará a palavra “love” às palavras ‘I” e “you” a um peso maior do que a palavra “Hello”. Pela linguística, sabemos que essas palavras compartilham uma relação sujeito-verbo-objeto e essa é uma maneira intuitiva de entender o que a Auto-Atenção irá capturar.
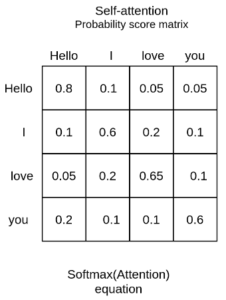
Na prática, o Transformer usa 3 representações diferentes: as consultas, chaves e valores da matriz de embedding. Isso pode ser feito facilmente multiplicando nossa entrada representada pela expressão abaixo:
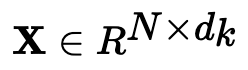
com 3 matrizes de peso diferentes, Wq, Wk e Wv. Em essência, é apenas uma multiplicação de matrizes de embeddings. O diagrama abaixo mostra como isso funciona:
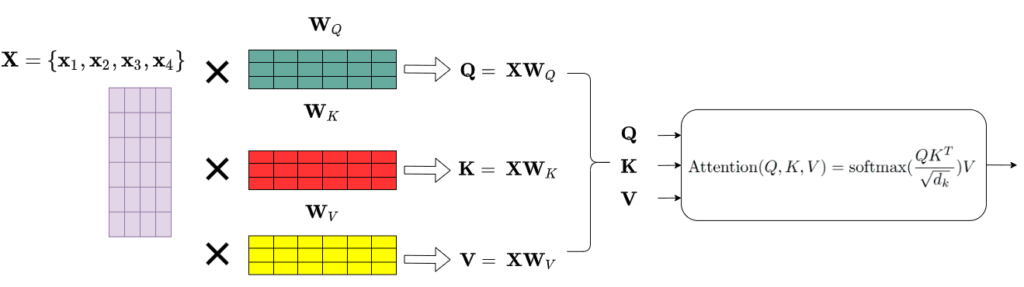
Tendo as matrizes Query (Q), Key (K) e Value (V), agora podemos aplicar a camada de Auto-Atenção como:
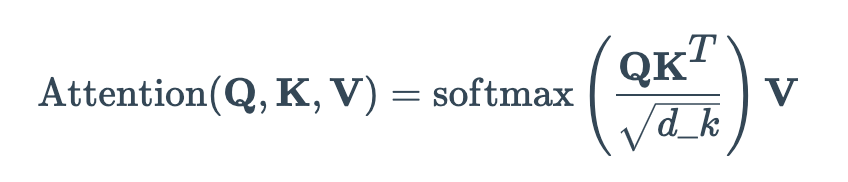
No artigo original dos Transformadores, a atenção do produto escalonado foi escolhida como uma função de pontuação para representar a correlação entre duas palavras (o peso da atenção). Observe que também podemos utilizar outra função de similaridade. A raiz quadrada de d_k na fórmula acima age simplesmente como um fator de escala para garantir que os vetores não explodam.
Este termo simplesmente encontra a similaridade da consulta de pesquisa com uma entrada em um banco de dados. Finalmente, aplicamos uma função softmax para obter os pesos finais de atenção como uma distribuição de probabilidade (da mesma forma que fazemos em diversos modelos de Deep Learning para classificação).
Lembre-se de que distinguimos as Chaves (K) dos Valores (V) como representações distintas. Assim, a representação final é a matriz de Auto-Atenção (a expressão com softmax na fórmula acima) multiplicada pela matriz de valores V.
Podemos pensar na matriz de Auto-Atenção como para onde olhar e na matriz de valor como o que eu realmente quero obter.
E aqui há um detalhes sobre a similaridade do vetor:
Primeiro, temos matrizes em vez de vetores e, como resultado, multiplicações de matrizes. Em segundo lugar, não diminuímos pela magnitude do vetor, mas pelo tamanho da matriz (d_k), que é o número de palavras em uma frase! E o tamanho da frase varia. 🙂
O que faríamos a seguir?
Normalização e conexões de salto curto, semelhantes ao processamento de um tensor após convolução (CNN) ou recorrência (RNN). Mas deixamos isso para o próximo capítulo. Até lá.
Referências:
Deep Learning Para Aplicações de Inteligência Artificial
Understanding Attention In Deep Learning
How Transformers work in deep learning and NLP: an intuitive introduction