

Capítulo 87 – Como Funcionam os Transformadores em Processamento de Linguagem Natural – Parte 2
Vamos seguir com a continuação do capítulo anterior. Este capítulo fornece algumas informações básicas necessárias para compreender o conceito por trás da autoatenção que veremos no capítulo seguinte.
Atenção Baseada em Recursos: Chave, Valor e Consulta
Os conceitos de consulta de chave-valor vêm de sistemas de recuperação de informações. É extremamente útil esclarecer esses conceitos primeiro.
Vamos começar com um exemplo de busca de um vídeo no youtube.
Quando você pesquisa (consulta) um vídeo específico, o mecanismo de pesquisa mapeia sua consulta em relação a um conjunto de chaves (título do vídeo, descrição, etc.) associado a possíveis vídeos armazenados. Em seguida, o algoritmo apresentará os vídeos (valores) com as melhores correspondências. Esta é a base da pesquisa baseada em conteúdo / recursos.
Trazendo essa ideia para mais perto da atenção do transformador, temos algo assim:
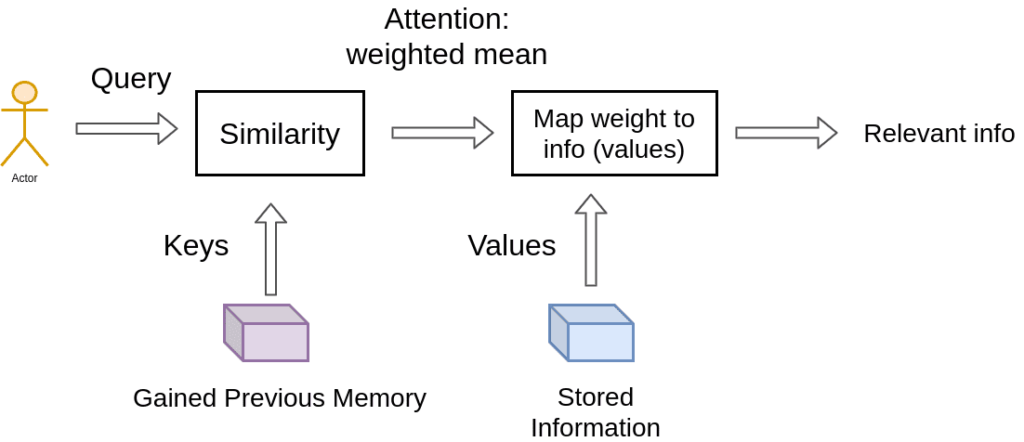
Na recuperação de um único vídeo, a atenção está na escolha do vídeo com pontuação máxima de relevância.
Mas podemos relaxar essa ideia. Para este fim, a principal diferença entre os sistemas de atenção e recuperação é que introduzimos uma noção mais abstrata e suave de “recuperação” de um objeto. Ao definir um grau de semelhança (peso) entre nossas representações (vídeos para o youtube), podemos ponderar nossa consulta.
Em vez de escolher onde olhar de acordo com a posição dentro de uma sequência, agora prestamos atenção ao conteúdo que queremos olhar!
Portanto, avançando um passo, dividimos ainda mais os dados em pares de chave-valor.
Usamos as chaves para definir os pesos de atenção para ver os dados e os valores como as informações que realmente obteremos.
Para o chamado mapeamento chave-valor, precisamos quantificar a similaridade, que veremos a seguir.
Semelhança Vetorial em Espaços Dimensionais Elevados
Em geometria, o produto vetorial interno é interpretado como uma projeção vetorial. Uma maneira de definir a similaridade do vetor é computar o produto interno normalizado.
No espaço de baixa dimensão, como o exemplo 2D abaixo, isso corresponderia ao valor do cosseno.
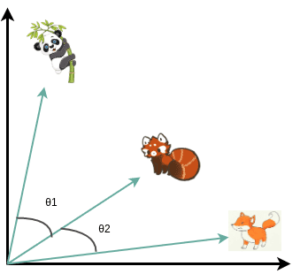
Matematicamente:
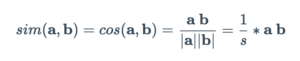
Podemos associar a semelhança entre os vetores que representam qualquer coisa (por exemplo, animais) calculando o produto escalar, ou seja, o cosseno do ângulo.
Em transformadores, esta é a operação mais básica e é tratada pela camada de autoatenção, como veremos no capítulo seguinte.
Referências:
Deep Learning Para Aplicações de Inteligência Artificial
Understanding Attention In Deep Learning
How Transformers work in deep learning and NLP: an intuitive introduction