

Capítulo 40 – Introdução às Redes Neurais Convolucionais
Nos primeiros capítulos deste livro ensinamos nossas redes neurais a fazer um bom trabalho reconhecendo imagens de dígitos manuscritos:
Fizemos isso usando redes nas quais camadas adjacentes são totalmente conectadas umas às outras. Ou seja, todos os neurônios da rede estão conectados a todos os neurônios em camadas adjacentes:
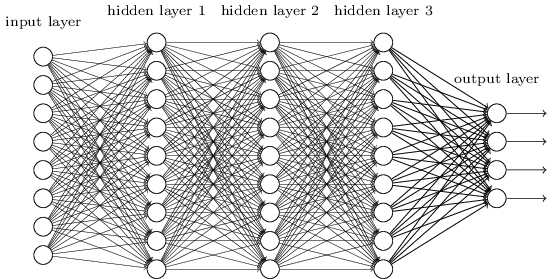
Em particular, para cada pixel na imagem de entrada, codificamos a intensidade do pixel como o valor de um neurônio correspondente na camada de entrada. Para as imagens de 28 × 28 pixels que estamos usando, isso significa que nossa rede tem 784 (= 28 × 28) neurônios de entrada. Em seguida, treinamos os pesos e vieses da rede para que a saída da rede identificasse corretamente a imagem de entrada: ‘0’, ‘1’, ‘2’, …, ‘8’ ou ‘9’.
Nossas redes anteriores funcionam muito bem: obtivemos uma precisão de classificação melhor que 98%, usando dados de treinamento e teste do conjunto de dados de dígitos manuscritos MNIST. Mas, após reflexão, é estranho usar redes com camadas totalmente conectadas para classificar imagens. A razão é que tal arquitetura de rede não leva em conta a estrutura espacial das imagens.
Por exemplo, ela trata os pixels de entrada que estão distantes e próximos exatamente no mesmo nível. Tais conceitos de estrutura espacial devem ser inferidos dos dados de treinamento. Mas e se, em vez de começarmos com uma arquitetura de rede que é rasa, utilizássemos uma arquitetura que tenta tirar proveito da estrutura espacial? É onde entram as redes neurais convolucionais.
Essas redes usam uma arquitetura especial que é particularmente bem adaptada para classificar imagens. O uso dessa arquitetura torna as redes convolucionais rápidas de treinar. Isso, por sua vez, nos ajuda a treinar redes profundas de muitas camadas, que são muito boas na classificação de imagens. Hoje, redes neurais convolucionais ou alguma variante próxima são usadas na maioria das redes neurais para reconhecimento de imagem.
As origens das redes neurais convolucionais remontam aos anos 70. Mas o artigo seminal que estabeleceu o tema moderno das redes convolucionais foi um artigo de 1998, “Gradient-based learning applied to document recognition“, de Yann LeCun, Léon Bottou, Yoshua Bengio e Patrick Haffner. Desde então, LeCun fez uma observação interessante sobre a terminologia para redes convolucionais: “A inspiração neural [biológica] em modelos como redes convolucionais é muito tênue. É por isso que eu os chamo de ‘redes convolucionais’ e não ‘redes neurais convolucionais’, e por isso os nós eu chamo de ‘unidades’ e não ‘neurônios’ “.
Apesar desta observação, as redes convolucionais usam muitas das mesmas ideias que as redes neurais que estudamos até agora: ideias como retropropagação, gradiente descendente, regularização, funções de ativação não lineares e assim por diante. E assim, vamos seguir a prática comum e considerá-las um tipo de rede neural. Usarei os termos “rede neural convolucional” e “rede convolucional” alternadamente. Também usarei os termos “neurônio [artificial]” e “unidade” alternadamente.
Definição
Uma Rede Neural Convolucional (ConvNet / Convolutional Neural Network / CNN) é um algoritmo de Aprendizado Profundo que pode captar uma imagem de entrada, atribuir importância (pesos e vieses que podem ser aprendidos) a vários aspectos / objetos da imagem e ser capaz de diferenciar um do outro. O pré-processamento exigido em uma ConvNet é muito menor em comparação com outros algoritmos de classificação. Enquanto nos métodos primitivos os filtros são feitos à mão, com treinamento suficiente, as ConvNets têm a capacidade de aprender esses filtros / características.
A arquitetura de uma ConvNet é análoga àquela do padrão de conectividade de neurônios no cérebro humano e foi inspirada na organização do Visual Cortex. Os neurônios individuais respondem a estímulos apenas em uma região restrita do campo visual conhecida como Campo Receptivo. Uma coleção desses campos se sobrepõe para cobrir toda a área visual. Veremos isso em detalhes mais a frente!
Por que usar ConvNets e não rede feed-forward?
Uma imagem não é nada além de uma matriz de valores de pixels, certo? Então, por que não apenas achatar a imagem (por exemplo, converter uma matriz 3×3 em um vetor 9×1. Se a image é uma matriz, nenhum problema em converter em uma vetor) e alimentá-lo para um Perceptron Multi-Layer para fins de classificação? Na verdade não.
Em casos de imagens binárias extremamente básicas, o método pode mostrar uma pontuação de precisão média durante a previsão de classes, mas teria pouca ou nenhuma precisão quando se trata de imagens complexas com dependências de pixel por toda parte.
Uma ConvNet é capaz de capturar com sucesso as dependências espaciais e temporais em uma imagem através da aplicação de filtros relevantes. A arquitetura executa um melhor ajuste ao conjunto de dados da imagem devido à redução no número de parâmetros envolvidos e à capacidade de reutilização dos pesos. Em outras palavras, a rede pode ser treinada para entender melhor a sofisticação da imagem.
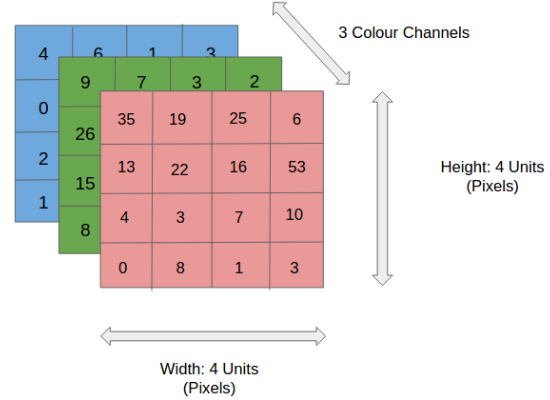
Na figura acima, temos uma imagem RGB (Red – Green – Blue) que foi separada por seus três planos coloridos – Vermelho, Verde e Azul. Existem vários desses espaços de cores nos quais existem imagens – Escala de cinza, RGB, HSV, CMYK etc.
Você pode imaginar como a computação ficaria intensiva assim que as imagens atingissem dimensões, digamos, 8K (7680 × 4320). A função da ConvNet é reduzir as imagens para uma forma mais fácil de processar, sem perder recursos que são críticos para obter uma boa previsão. Isso é importante quando queremos projetar uma arquitetura que não seja apenas boa em recursos de aprendizado, mas que também seja escalável para conjuntos de dados massivos.
Essa é uma das arquiteturas de Deep Learning mais incríveis e com mais aplicações práticas e dedicaremos alguns capítulos a este arquitetura.
As redes neurais convolucionais usam três ideias básicas: campos receptivos locais, pesos compartilhados e pooling. Vamos dar uma olhada em cada uma dessas ideias? Então não perca os próximos capítulos!
Referências:
Inteligência Artificial Para Visão Computacional
Don’t Decay the Learning Rate, Increase the Batch Size
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
A Comprehensive Guide to Convolutional Neural Networks
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition