

Capítulo 89 – Como Funcionam os Transformadores em Processamento de Linguagem Natural – Parte 4
Vamos prosseguir estudando os transformadores. Este capítulo considera que você leu os capítulos anteriores.
Conexões Residuais de Salto Curto
Na linguagem, existe uma noção significativa de uma compreensão mais ampla do mundo e de nossa capacidade de combinar ideias. Os humanos utilizam amplamente essas influências de cima para baixo (nossas expectativas) para combinar palavras em diferentes contextos. De uma maneira bem simples, as conexões de salto curto fornecem a um transformador uma pequena capacidade de permitir que as representações de diferentes níveis de processamento interajam.
Com a formação de vários caminhos, podemos “passar” nosso entendimento de nível superior das últimas camadas do modelo, para as camadas anteriores. Isso nos permite remodular como entendemos a entrada. Novamente, essa é a mesma ideia do entendimento humano de cima para baixo, que nada mais é do que expectativas.
Normalização de Camada
A seguir, vamos abrir a caixa preta do Layer Norm ou apenas LN (Normalização de Camada).
Na normalização de camada (LN), a média e a variância são calculadas entre canais e dimensões espaciais. Na linguagem, cada palavra é um vetor. Como estamos lidando com vetores, temos apenas uma dimensão espacial (mais detalhes sobre isso em Matemática e Estatística Aplicada Para Data Science, Machine Learning e IA).
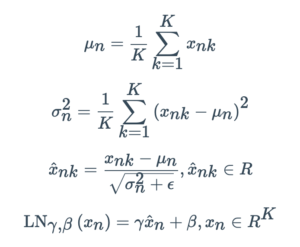
Em um tensor 4D com dimensões espaciais combinadas, podemos visualizar isso com a seguinte figura:
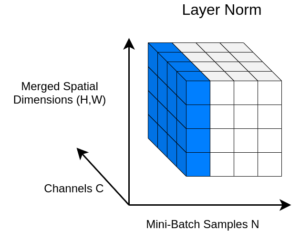
Depois de aplicar uma camada de normalização e formar uma conexão residual de salto curto, estamos aqui:
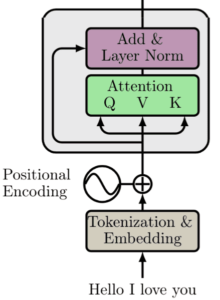
Mesmo que este possa ser um bloco de construção autônomo, os criadores do transformador adicionam outra camada linear na parte superior e a renormalizam junto com outra conexão de salto curto.
Camada Linear
Na sequência, os autores adicionaram uma camada linear à arquitetura. A intuição principal é que eles projetam a saída da auto-atenção em um espaço dimensional superior (ideia muito similar ao que é feito no algoritmo SVM). Isso resolve inicializações ruins e colapso de classificação. Mas vamos representá-lo nos diagramas simplesmente como Linear.
Esta é a parte do codificador do transformador com N blocos de construção, conforme ilustrado abaixo:
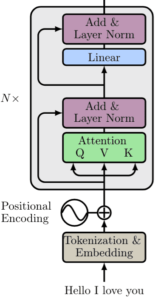
Na verdade, este é quase o codificador do transformador. Existe uma diferença. Atenção multi-cabeça (multi-head attention). No artigo original, os autores expandem a ideia de auto-atenção para a multi-head attention. Em essência, passamos pelo mecanismo de atenção várias vezes, conforme ilustrado na imagem abaixo:
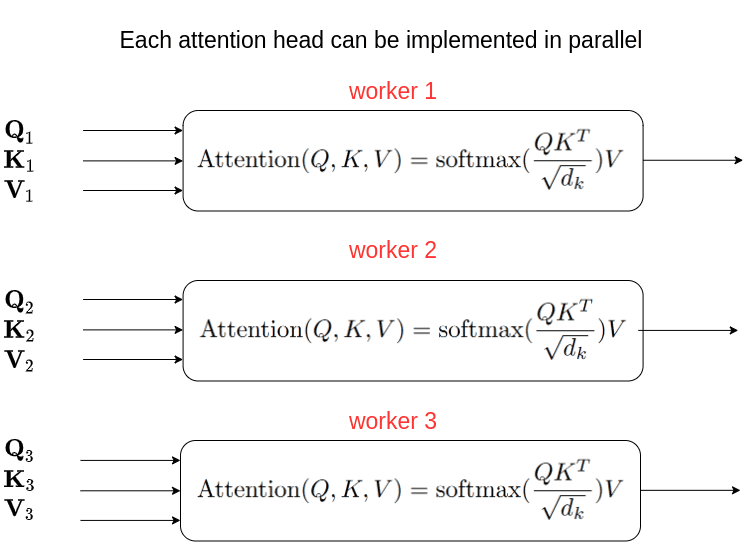
Mas por que passar por todos esses problemas?
A intuição por trás da atenção com várias cabeças é que ela nos permite atender a diferentes partes da sequência de maneira diferente a cada vez. Isso praticamente significa que:
1- O modelo pode capturar melhor as informações posicionais porque cada cabeça atenderá a diferentes segmentos da entrada. A combinação deles nos dará uma representação mais robusta.
2- Cada cabeça também irá capturar diferentes informações contextuais, correlacionando palavras de uma maneira única.
Não perca o objetivo de vista. Tudo isso que é feito no Transformador tem um objetivo: criar Inteligência Artificial para o Processamento de Linguagem Natural, sendo esta uma das técnicas mais avançadas da atualidade.
Agora estamos em condições de resumir tudo que vimos até aqui e construir a arquitetura do Transformador. Exatamente o tema do próximo capítulo. Até lá.
Referências:
Deep Learning Para Aplicações de Inteligência Artificial
Formação Processamento de Linguagem Natural 4.0
Understanding Attention In Deep Learning
How Transformers work in deep learning and NLP: an intuitive introduction