

Capítulo 84 – CLIP (Contrastive Language Image Pre-training): Conectando Texto e Imagens
O ano de 2021 começou com um estrondo! A OpenAI lançou duas grandes inovações no campo da Visão Computacional: CLIP e DALL-E.
A rede CLIP tem uma abordagem realmente interessante e possivelmente revolucionária para tarefas de classificação de imagens usando o pré-treinamento contrastante para realizar o aprendizado zero-shot semelhante ao do GPT-3, que abordamos em capítulos anteriores.
Embora o aprendizado profundo (Deep Learning) tenha revolucionado a Visão Computacional, as abordagens atuais têm vários problemas: conjuntos de dados de visão computacional típicos são trabalhosos e caros para criar, enquanto ensinam apenas um conjunto estreito de conceitos visuais; os modelos de visão computacional padrão são bons em uma tarefa e apenas em uma tarefa, e requerem um esforço significativo para se adaptar a uma nova tarefa; e os modelos que apresentam bom desempenho em benchmarks apresentam desempenho decepcionantemente ruim em testes de estresse, lançando dúvidas sobre toda a abordagem de aprendizado profundo para visão computacional.
Mas a OpenAI criou uma rede neural que visa resolver esses problemas: é treinada em uma ampla variedade de imagens com uma ampla variedade de supervisão de linguagem natural que está abundantemente disponível na internet. Por design, a rede pode ser instruída em linguagem natural para realizar uma grande variedade de benchmarks de classificação, sem otimizar diretamente para o desempenho do benchmark, semelhante aos recursos de “tiro zero” (Zero-Shot) do GPT-2 e GPT-3. Esta é uma mudança importante: ao não otimizar diretamente para o benchmark, o modelo se torna muito mais representativo e o sistema fecha essa “lacuna de robustez” em até 75%, ao mesmo tempo em que iguala o desempenho do ResNet-50 original no ImageNet zero-shot sem usar nenhum dos os exemplos rotulados de 1,28M originais.
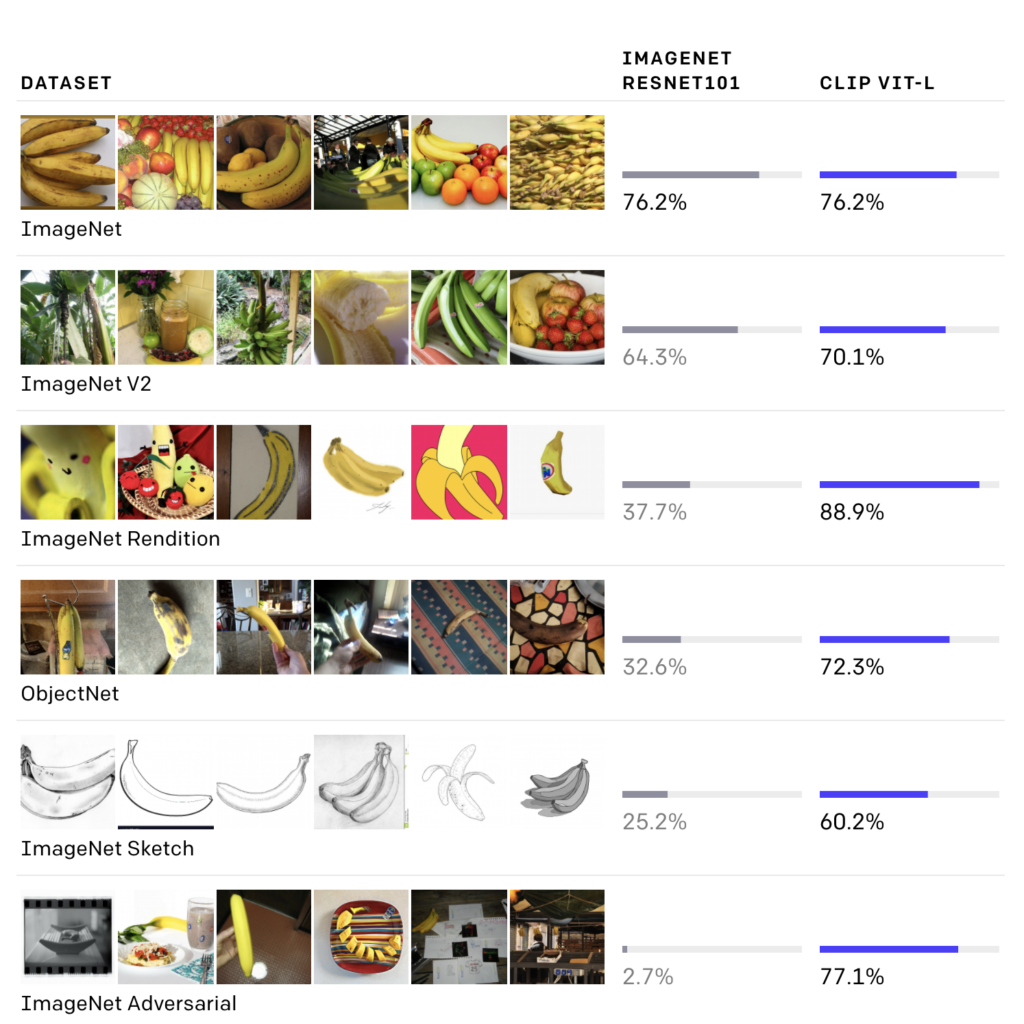
Embora os dois modelos acima tenham a mesma precisão no conjunto de teste ImageNet, o desempenho do CLIP é muito mais representativo de como se sairá em conjuntos de dados que medem a precisão em diferentes configurações não ImageNet. Por exemplo, ObjectNet verifica a capacidade de um modelo de reconhecer objetos em muitas poses diferentes e com muitos fundos diferentes dentro de casas, enquanto ImageNet Rendition e ImageNet Sketch verificam a capacidade de um modelo de reconhecer representações mais abstratas de objetos.
O Que e CLIP Tenta Resolver?
Antes de entender como o CLIP funciona, vamos ver o que a OpenAI pretende resolver.
Temos visto grandes melhorias na visão computacional para resolver uma infinidade de problemas, mas cada uma delas vem com suas desvantagens, como:
Muitos modelos de visão computacional atuais, como ResNet e InceptionNet, são capazes de atingir desempenho de nível humano em conjuntos de dados de classificação de imagens complexos, no entanto, eles precisam da disponibilidade de grandes conjuntos de dados, o que é difícil de criar.
Mesmo que os modelos de última geração possam ter um desempenho extremamente bom em conjuntos de dados como ImageNet, eles caem drasticamente quando introduzidos em variantes ou dados prontos para uso, pois foram otimizados apenas para desempenho no benchmark e falham em desempenho em cenários da vida real .
O OpenAI visa resolver esses problemas de grandes conjuntos de dados e desempenho ruim na vida real com o CLIP. O CLIP não só provou fornecer resultados de última geração na classificação de imagens, mas também outras tarefas de visão, como classificação de objetos, reconhecimento de ações em vídeos e OCR. Isso mostra que um único algoritmo como o CLIP pode trabalhar com uma variedade de tarefas e conjuntos de dados sem a necessidade de construir conjuntos de dados enormes, mas é caro do ponto de vista computacional.
O CLIP também desempenha um papel vital no funcionamento do DALL-E, que amos abordar nos capítulos seguintes!
Compreendendo a Arquitetura CLIP
CLIP (Contrastive Language – Image Pre-training) baseia-se em um grande corpus de trabalho em transferência zero-shot, supervisão de linguagem natural e aprendizagem multimodal. A ideia de aprendizado de dados zero-shot remonta a mais de uma década, mas até recentemente era estudada principalmente em visão computacional como uma forma de generalizar para categorias de objetos invisíveis. Um insight crítico foi alavancar a linguagem natural como um espaço de previsão flexível para permitir a generalização e transferência. Em 2013, Richer Socher e coautores em Stanford desenvolveram uma prova de conceito treinando um modelo no dataset CIFAR-10 para fazer previsões em um espaço de incorporação de vetores de palavras e mostraram que esse modelo poderia prever duas classes invisíveis. No mesmo ano, DeVISE escalou essa abordagem e demonstrou que era possível ajustar um modelo ImageNet para que pudesse generalizar para prever corretamente objetos fora do conjunto de treinamento original.
Mais inspirador para o CLIP é o trabalho de Ang Li e seus co-autores na FAIR, que em 2016 demonstrou o uso de supervisão de linguagem natural para permitir a transferência zero-shot para vários conjuntos de dados de classificação de visão computacional existentes, como o conjunto de dados ImageNet. Eles conseguiram isso ajustando um modelo ImageNet CNN (Convolutional Neural Network, que estudamos ao longo deste livro) para prever um conjunto muito mais amplo de conceitos visuais (visuais n-gramas) a partir do texto de títulos, descrições e tags de 30 milhões de fotos do Flickr e foram capazes de alcançar 11,5% de precisão no ImageNet tiro zero.
Finalmente, CLIP faz parte de um grupo de artigos que revisitam a aprendizagem de representações visuais a partir da supervisão de linguagem natural. Esta linha de trabalho usa arquiteturas mais modernas como o Transformer e inclui VirTex, que explorou a modelagem de linguagem autoregressiva, ICMLM, que investigou a modelagem de linguagem mascarada, e ConVIRT, que estudou o mesmo objetivo contrastivo usado no CLIP, mas no campo de imagens médicas.
Não é incrível estarmos escrevendo neste momento a história da Inteligência Artificial que vai impactar a história da própria humanidade ao longo dos próximos anos? Se você concorda, acompanhe os próximos capítulos.
Referências:
CLIP: Connecting Text and Images
A study and comparison of human and deep learning recognition performance under visual distortions
Strike (with) a pose: Neural networks are easily fooled by strange poses of familiar objects.
Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models