

Capítulo 23 – Como Funciona o Dropout?
Dropout é uma técnica radicalmente diferente para regularização. Ao contrário da Regularização L1 e L2, o Dropout não depende da modificação da função de custo. Em vez disso, no Dropout, modificamos a própria rede. Deixe-me descrever a mecânica básica de Como Funciona o Dropout? antes de entender porque ele funciona e quais são os resultados. Suponha que estamos tentando treinar uma rede neural:
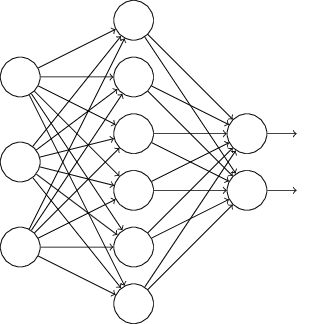
Em particular, suponha que tenhamos uma entrada de treinamento x e a saída desejada correspondente y. Normalmente, nós treinamos pela propagação direta de x através da rede, e depois retrocedemos (retropropagação) para determinar a contribuição do erro para o gradiente. Com o Dropout, esse processo é modificado. Começamos por eliminar aleatoriamente (e temporariamente) alguns dos neurônios ocultos na rede, deixando os neurônios de entrada e saída intocados. Depois de fazer isso, terminaremos com uma rede da seguinte forma (observe as linhas tracejadas na figura abaixo). Note os neurônios que foram temporariamente eliminados:
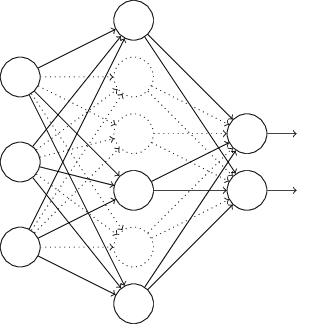
Nós encaminhamos para frente a entrada x através da rede modificada, e depois retropropagamos o resultado, também através da rede modificada. Depois de fazer isso em um mini-lote de exemplos, atualizamos os pesos e vieses apropriados. Em seguida, repetimos o processo, primeiro restaurando os neurônios removidos, depois escolhendo um novo subconjunto aleatório de neurônios ocultos para excluir, estimando o gradiente para um mini-lote diferente e atualizando os pesos e vieses na rede.
Ao repetir esse processo várias vezes, nossa rede aprenderá um conjunto de pesos e vieses. Naturalmente, esses pesos e vieses terão sido aprendidos sob condições em que parte dos neurônios ocultos foram descartados. Quando realmente executamos a rede completa, isso significa que mais neurônios ocultos estarão ativos. Para compensar isso, reduzimos pela metade os pesos que saem dos neurônios ocultos.
Esse procedimento de desistência pode parecer estranho e ad-hoc. Por que esperamos que ajude com a regularização? Para explicar o que está acontecendo, gostaria que você parasse brevemente de pensar sobre o Dropout e, em vez disso, imagine o treinamento de redes neurais no modo padrão (sem Dropout). Em particular, imagine que treinamos várias redes neurais diferentes, todas usando os mesmos dados de treinamento.
É claro que as redes podem não começar idênticas e, como resultado, após o treinamento, elas podem, às vezes, dar resultados diferentes. Quando isso acontece, podemos usar algum tipo de esquema de média ou votação para decidir qual saída aceitar. Por exemplo, se nós treinamos cinco redes, e três delas estão classificando um dígito como um “3”, então provavelmente é um “3”. As outras duas redes provavelmente estão cometendo um erro. Este tipo de esquema de média é frequentemente encontrado como uma maneira poderosa (embora requeira mais capacidade computacional) de reduzir o overfitting. A razão é que as diferentes redes podem se sobrepor de diferentes maneiras e a média pode ajudar a eliminar esse tipo de overfitting.
O que isso tem a ver com o Dropout? Heuristicamente, quando abandonamos diferentes conjuntos de neurônios, é como se estivéssemos treinando redes neurais diferentes. E assim, o procedimento de eliminação é como calcular a média dos efeitos de um grande número de redes diferentes. As diferentes redes se adaptarão de diferentes maneiras, e assim, esperançosamente, o efeito líquido do Dropout será reduzir o overfitting.
Uma explicação heurística relacionada ao Dropout é dada em um dos primeiros artigos a usar a técnica: “Esta técnica reduz co-adaptações complexas de neurônios, já que um neurônio não pode confiar na presença de outros neurônios em particular. É, portanto, forçado a aprenda recursos mais robustos que são úteis em conjunto com muitos subconjuntos aleatórios diferentes dos outros neurônios”. Em outras palavras, se pensarmos em nossa rede como um modelo que está fazendo previsões, então podemos pensar no Dropout como uma forma de garantir que o modelo seja robusto para a perda de qualquer evidência individual. Nesse ponto, é um pouco semelhante à Regularização L1 e L2, que tendem a reduzir os pesos e, assim, tornar a rede mais robusta para perder qualquer conexão individual na rede.
Naturalmente, a verdadeira medida do Dropout é que ele foi muito bem sucedido em melhorar o desempenho das redes neurais. O artigo original, introduzindo a técnica, aplicou-a a muitas tarefas diferentes. Para nós, é de particular interesse que eles aplicaram o Dropout na classificação de dígitos MNIST, usando uma rede neural feedforward “vanilla” ao longo de linhas similares àquelas que estamos considerando. O documento observou que o melhor resultado que alguém alcançou até aquele ponto usando tal arquitetura foi a precisão de classificação de 98,4% no conjunto de testes. Eles melhoraram isso para 98,7% de precisão usando uma combinação de Dropout e uma forma modificada de Regularização L2. Da mesma forma, resultados impressionantes foram obtidos para muitas outras tarefas, incluindo problemas de reconhecimento de imagem e fala e processamento de linguagem natural. O Dropout tem sido especialmente útil no treinamento de redes grandes e profundas, nas quais o problema do overfitting é frequentemente agudo.
Até o próximo capítulo!
Referências:
Formação Engenheiro de Inteligência Artificial
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition
Gradient Descent For Machine Learning
Pattern Recognition and Machine Learning
Understanding Activation Functions in Neural Networks
Redes Neurais, princípios e práticas
ImageNet Classification with Deep Convolutional Neural Networks
Improving neural networks by preventing co-adaptation of feature detectors