

Capítulo 28 – Usando Early Stopping Para Definir o Número de Épocas de Treinamento
Ao treinar redes neurais, várias decisões precisam ser tomadas em relação às configurações (hiperparâmetros) usadas, a fim de obter um bom desempenho. Um desses hiperparâmetros é o número de épocas de treinamento: ou seja, quantas passagens completas do conjunto de dados (épocas) devem ser usadas? Se usarmos poucas épocas, poderemos ter problemas de underfitting (ou seja, não aprender tudo o que pudermos com os dados de treinamento); se usarmos muitas épocas, podemos ter o problema oposto, overfitting (“aprender demais”, ou seja, ajustar o “ruído” nos dados de treinamento, e não o sinal).
Usamos o Early Stopping (“Parada Antecipada” ou “Parada Precoce”) exatamente para tentar definir manualmente esse valor. Também pode ser considerado um tipo de método de regularização (como L1/L2 weight decay e dropout estudados anteriormente aqui no livro), pois pode impedir o overfitting da rede neural. A imagem abaixo ajuda a definir claramente o que é o Early Stopping:
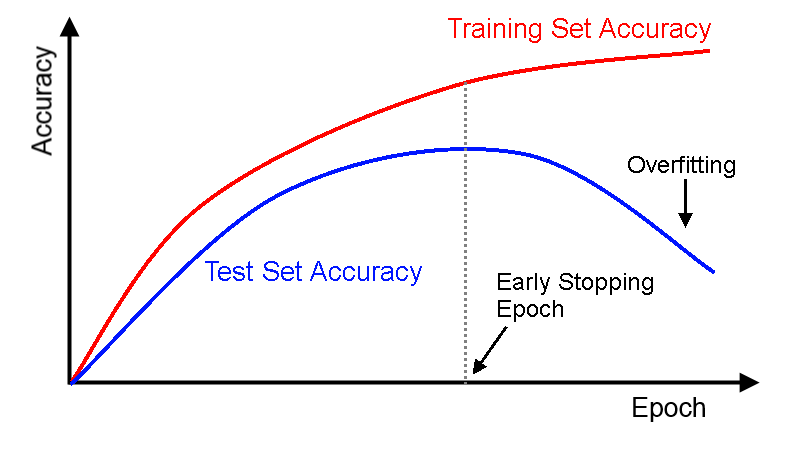
Ao treinar uma rede neural, geralmente se está interessado em obter uma rede com desempenho ideal de generalização. No entanto, todas as arquiteturas de rede neural padrão, como o perceptron multicamada totalmente conectado, são propensas a overfitting. Enquanto a rede parece melhorar, isto é, o erro no conjunto de treinamento diminui, em algum momento durante o treinamento na verdade começa a piorar novamente, ou seja, o erro em exemplos invisíveis aumenta.
Normalmente, o erro de generalização é estimado pelo erro de validação, isto é, o erro médio em um conjunto de validação, um conjunto fixo de exemplos que não são do conjunto de treino. Existem basicamente duas maneiras de combater o overfitting: reduzindo o número de dimensões do espaço de parâmetros ou reduzindo o tamanho efetivo de cada dimensão. Técnicas para reduzir o número de parâmetros são aprendizagem construtiva gananciosa, poda ou compartilhamento de peso. Técnicas para reduzir o tamanho de cada dimensão de parâmetro são a regularização, como weight decay ou dropout, ou a Parada Precoce (Early Stopping). A parada precoce é amplamente usada porque é simples de entender e implementar e foi relatada como sendo superior aos métodos de regularização em muitos casos.
Usar Early Stopping significa que, no final de cada época, devemos calcular a precisão da classificação nos dados de validação. Quando a precisão parar de melhorar, terminamos o treinamento. Isso torna a configuração do número de épocas muito simples. Em particular, isso significa que não precisamos nos preocupar em descobrir explicitamente como o número de épocas depende dos outros hiperparâmetros, pois isso é feito automaticamente. Além disso, a Parada Antecipada também impede automaticamente o overfitting. Isto é, obviamente, uma coisa boa, embora nos estágios iniciais da experimentação possa ser útil desligar a Parada Antecipada, para que você possa ver quaisquer sinais de overfitting e usá-los para definir sua abordagem de regularização.
Para implementar a Parada Antecipada, precisamos dizer com mais precisão o que significa que a precisão da classificação parou de melhorar. Como já vimos, a precisão pode se mover um pouco, mesmo quando a tendência geral é melhorar. Se pararmos pela primeira vez, a precisão diminui, então quase certamente pararemos quando houver mais melhorias a serem feitas. Uma regra melhor é terminar se a melhor precisão de classificação não melhorar por algum tempo. Suponha, por exemplo, que estamos trabalhando com o dataset MNIST. Poderíamos optar por terminar se a precisão da classificação não melhorou durante as últimas dez épocas. Isso garante que não paremos cedo demais, em resposta à má sorte no treinamento, mas também que não estamos esperando para sempre uma melhoria que nunca acontece.
Esta regra de “parar o treinamento se não melhorar em dez épocas” é boa para a exploração inicial do MNIST. No entanto, as redes podem às vezes estabilizar-se perto de uma determinada precisão de classificação por algum tempo, apenas para começar a melhorar novamente. Se você está tentando obter um desempenho realmente bom, a regra de “parar o treinamento se não melhorar em dez épocas” pode ser muito agressiva. Nesse caso, sugerimos usar essa regra para a experimentação inicial e, gradualmente, adotar regras mais brandas, conforme entender melhor a maneira como sua rede treina: sem melhoria em vinte épocas, sem melhoria em cinquenta épocas e assim por diante. Claro, isso introduz um novo hiperparâmetro para otimizar! Na prática, no entanto, geralmente é fácil definir esse hiperparâmetro para obter bons resultados. Da mesma forma, para problemas diferentes do MNIST, a regra de não-melhoria-em-dez pode ser agressiva demais ou não ser agressiva o suficiente, dependendo dos detalhes do problema. No entanto, com um pouco de experimentação, geralmente é fácil encontrar uma boa estratégia para o Early Stopping. Isso faz parte do trabalho do Cientista de Dados ou do Engenheiro de Inteligência Artificial.
Até aqui, nós não usamos o Early Stopping em nossos experimentos MNIST. A razão é que temos feito muitas comparações entre diferentes abordagens de aprendizado. Para tais comparações, é útil usar o mesmo número de épocas em cada caso. No entanto, vale a pena modificar o network2.py para implementar o Early Stopping, e deixaremos isso como tarefa para você. Se precisar de ajuda, o Early Stopping é estudado em detalhes aqui.
Até o próximo capítulo!
Referências:
Formação Linguagem Python Para Data Science
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition