

Capítulo 46 – Reconhecimento de Imagens com Redes Neurais Convolucionais em Python – Parte 3
Uma das principais dúvidas de quem está iniciando em Machine Learning e se depara com as Redes Neurais Convolucionais, é sobre como ocorre o aprendizado dos parâmetros (aquilo que o algoritmo realmente aprende durante o treinamento). O que exatamente está sendo feito quando apresentamos uma imagem a um algoritmo de Rede Neural Convolucional?

Sabemos que em cada camada de convolução, a rede tenta entender os padrões básicos. Por exemplo: Na primeira camada de convolução, a rede tenta aprender padrões e bordas das imagens. Na segunda camada, ela tenta entender a forma / cor e outras coisas. Uma camada final chamada camada de recurso / camada totalmente conectada tenta classificar a imagem.
Antes de prepararmos o script com nossa rede convolucional, vamos compreender como definimos a arquitetura da rede e em quais camadas os parâmetros são aprendidos.
Camada de Entrada (Input Layer): O que a camada de entrada faz é ler a imagem. Portanto, não há parâmetros a serem aprendidos aqui.
Camada Convolucional (Convolutional Layer): considere uma camada convolucional que usa os mapas de recursos “l” como entrada e tem os mapas de recursos “k” como saída. O tamanho do filtro é “n * m”.
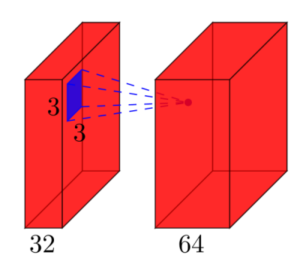
Aqui, a entrada tem l = 32 mapas de recursos como entradas, k = 64 mapas de recursos como saídas e o tamanho do filtro é n = 3 e m = 3. É importante entender que não temos apenas um filtro 3 * 3, mas, na verdade, temos um filtro 3 * 3 * 32, já que nossa entrada tem 32 dimensões. E como uma saída da primeira camada convolucional, aprendemos 64 diferentes filtros 3 * 3 * 32 cujo peso total é “n * m * k * l”. Depois, há um termo chamado bias para cada mapa de recursos. Portanto, o número total de parâmetros é “(n * m * l + 1) * k”.
Camada de Pooling (Pooling Layer): Não há parâmetros a aprender na camada de pooling. Essa camada é usada apenas para reduzir o tamanho da dimensão da imagem.
Obs: Podemos ter várias combinações de camada convolucional / camada de pooling em nossa arquitetura, sendo esta decisão do Cientista de Dados ou Engenheiro de Inteligência Artificial.
Camada Totalmente Conectada (Fully Connected Layer): Nesta camada, todas as unidades de entrada possuem um peso separável para cada unidade de saída. Para entradas “n” e saídas “m”, o número de pesos é “n * m”. Além disso, essa camada possui o bias para cada nó de saída, portanto, os parâmetros aprendidos são “(n + 1) * m”.
Camada de Saída (Output Layer): Esta camada é totalmente conectada, portanto, os parâmetros aprendidos também são “(n + 1) m”, quando “n” é o número de entradas e “m” é o número de saídas.
A principal dificuldade ao definir a arquitetura de um CNN é a primeira camada totalmente conectada. Não sabemos a dimensionalidade da camada totalmente conectada. Para calcular isso, temos que começar com o tamanho da imagem de entrada e calcular o tamanho de cada camada convolucional.
No caso simples, o tamanho da camada totalmente conectada é calculado como “input_size – (filter_size – 1)”. Por exemplo, se o tamanho da imagem de entrada for (50,50) e o filtro for (3,3), então (50- (3-1)) = 48. Mas o tamanho da imagem de entrada de uma rede convolucional não deve ser menor que a entrada, então precisamos definir o padding.
Para calcular o padding usamos: input_size + 2 * padding_size – (filter_size-1). Para o caso acima, (50 + (2 * 1) – (3–1) = 52 – 2 = 50) que fornece o mesmo tamanho de entrada. Perfeito, pois assim não perdemos nenhum detalhe da imagem. Se quisermos explicitamente diminuir a imagem durante a convolução, podemos definir um passo (stride).
Finalmente, para calcular o número de parâmetros que a rede vai aprender usamos: (n * m * k + 1) * f. Veremos tudo isso em código Python no próximo capítulo!
Caso queira mais detalhes sobre como definir a arquitetura da rede, consulte o famoso e excelente paper da AlexNet: ImageNet Classification with Deep Convolutional Neural Networks.
Referências:
ImageNet Classification with Deep Convolutional Neural Networks
Don’t Decay the Learning Rate, Increase the Batch Size
How to calculate the number of parameters in the CNN?
Practical Recommendations for Gradient-Based Training of Deep Architectures
Gradient-Based Learning Applied to Document Recognition
A Comprehensive Guide to Convolutional Neural Networks
Neural Networks & The Backpropagation Algorithm, Explained
Neural Networks and Deep Learning
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition